appCD Launches Generative Infrastructure from Code! Learn More
May 29, 2024 •Sabith K Soopy

Large Language Models (LLMs) are of increasing importance in the engineering world. Most companies developing software are considering how LLMs could improve their product and the user experience. At appCD, we are absolutely considering how to incorporate LLM into the processes around generating secure, consistent infrastructure as code.
I wanted to showcase some of the research we’ve been undertaking as part of that process, so that if you are considering LLMs it might get you started.
As a first step, it is important to understand the problem you are trying to solve. In our case, we know that infrastructure as code (IaC) is hard for many users to create and maintain. We also know that IaC can unintentionally cause security and compliance issues if not created properly. The problem we are trying to solve with LLMs is to make it easier for a user to generate IaC without having to understand all the complexities associated with policy selection, cloud provider and all the associated components.
Getting Started
In many products, you have internal terms and concepts that you put out in the world for prospects and customers to use. In our case, we use terms like appStacks, offer specific policies, etc. There can be a lot of new terms for an end user. The reality is they do not want to have to learn a new way of working. Instead, they want to provide a repo, select a cloud and have the infrastructure provisioned without having to figure out what policies are needed or what is the optimal packaging.
To solve this problem, we thought about the knowledge and context non DevSecOps people would need in order to create the most concise, secure infrastructure architecture. One challenge of using an LLM for any infrastructure solution is that it must be perfect. You cannot have a provisioning or deployment solution that only sort of understands the requirements, because no one will trust it and you’ll still face the challenges of doing it manually vs. automating.
Open Source LLM Options
As part of this exercise, we evaluated three different open source LLMs, but found that none quite understood infrastructure the way we want:
- Meta Llama 3: Meta describes Llama 3 as “an openly accessible model that excels at language nuances, contextual understanding, and complex tasks like translation and dialogue generation. Llama 3 can handle multi-step tasks effortlessly, while our refined post-training processes significantly lower false refusal rates, improve response alignment, and boost diversity in model answers. It drastically elevates capabilities like reasoning, code generation, and instruction following.”
- OpenAI: Probably the most well known at the moment, OpenAI provides LLM text generation models (often referred to as generative pre-trained transformers or "GPT" models for short), like GPT-4 and GPT-3.5. These models have been trained to understand natural and formal language. Models like GPT-4 allow text outputs in response to their inputs. The inputs to these models are also referred to as “prompts”.
- Google Gemini: Gemini is the AI-powered assistant from Google, built right into Gmail, Docs, Sheets, and more, with enterprise-grade security and privacy.
For each one of these, we realized that while great at conversations, they are not great at infrastructure. To make the user experience great, we need to teach these LLMs new tricks, essentially showing them: if you are faced with this problem, this is how you can solve it. In order to do that, we have to break down infrastructure requirements into very small parts.
Using Retrieval Augmented Generation to Train LLM
One limitation of, say, OpenAI is that its dataset is limited and doesn’t have the latest information available. As one blog defines it “LLMs are ‘frozen in time’ as their training data is inherently outdated, which means they cannot access the latest news or information.”
To overcome this, I spent time investigating Retrieval-Augmented Generation (RAG), an advanced technique that can significantly enhance the learning capabilities of LLMs. By integrating RAG, LLMs can access a wider, more current dataset that goes beyond their initial training data. This is particularly useful for keeping up with the latest information, which is vital in the fast-paced tech industry. RAG works by allowing the LLM to retrieve relevant data from updated sources when faced with a query. This reduces the chances of the model providing outdated or irrelevant information, a common pitfall known as 'hallucination'. Implementing RAG can thus lead to more accurate, context-aware responses from the LLM. As a result, the AI system becomes more reliable and effective in solving complex problems and answering user queries, ensuring that the advice it offers is both current and accurate.
Using a tool like RAG, we could train an LLM on infrastructure components and policies so that it doesn’t make up random words! (It does this by default, so beware!).
For RAGs, there are two main libraries: LlamaIndex and LangChain. Both support Python and TypeScript. During my experiment, the learning curve for LangChain was easier, made more sense and was faster. (I did start with LlamaIndex, but quickly pivoted). In fact, the ecosystem they have is awesome and how I would build it if starting from scratch.
Investigating LangChain and Weaviate
After selecting LangChain, I started using the ReAct paradigm with it. This allowed me to tell the LLM how to solve a problem by giving it instructions. For example, if I want to multiply three by ten. I need to teach it like I would a child. So you would go through the thoughts. Thought one: add 10 + 10 = 20. Thought two: 20+10 = 30.
Applying it to infrastructure provisioning, I might want to allow my user to ask a question like what are some policies that I need to protect my stateful, ecommerce website on AWS? Here we need to break this down and teach what this means point by point. On the backend, that requires us to define and educate the LLM on: when we see this, we provide these components.
In my experimentation, I provided three requests:
- You will be given a question about cloud infrastructure. You will figure out the cloud provider in lower case and the action being performed.
- You should figure out the services required to fulfill the action on the cloud.
- You should provide the final answer as a JSON object of cloud resources in HCL format.

In this example, I gave the LLM an answer for when a user asks “deploy web applications in AWS,” training it so the output would be “cloud_provider”: “aws” (see screenshot):
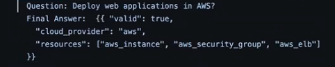
This example helps ensure LLMs do not make up words or hallucinate, because we can all agree that is very bad in infrastructure creation!
Forward-Looking LLM
The smart part of LLM (amongst other things), is that LLMs can be forward looking. It can capture a lot of the questions. In the above example, I talked about an e-commerce app. The LLM started to give me an answer. It wasn’t perfect, but it was directionally right.
Where this helps is reducing the barrier to using trained LLMs for infrastructure.
The Hardest Part
As part of the LLM evaluation, converting policies into a data set that RAG could use took longer than expected (and I’m still experimenting!). Essentially it requires the set up of all the surrounding infrastructure and components to support the LLM and make it work for the end user.
Because of the influx of LLM solutions, there are so many options on the market to support engineers as they create offers using the technology. Just weeding through the offers is a lot of work.
My Favorite Tools
One vendor that stood out is Ollama. It helps organizations get up and running with LLMs. Ollama can run on your machine and you do not have to pay for the service. I got it set up on my machine and effectively have a ChatGPT on my machine. I can ask for jokes, the meaning of my name, a Haiku. LangChain, as discussed earlier, was a standout ecosystem and tool, with a great, active community as well.
Advice for Developer Starting with LLMs
LLMs are like learning a new language. There will always be some friction, but after the initial barrier, you will get there. You do not need to spend any money to get a good understanding of LLMs and experiment with it. Use your imagination and LLM can help you come up with anything!